
KI-Parameter: Das Zusammenspiel von Temperature, Top-P und Presence Penalty einfach erklärt

Auf dem Papier könnte der Umgang mit LLMs (= Large Language Models) wie ChatGPT kaum einfacher sein: Man überträgt dem Tool eine Aufgabe, mit dem neuen Advanced Voice Mode ist dies nun auch per Sprachbefehl möglich, und bereits wenige Sekunden später serviert das LLM eine passende Antwort.
Schnell tun sich mit den ersten KI-Prompts aber auch die ersten Probleme auf, denn nicht immer wollen die Ergebnisse zu den eigenen Erwartungen passen. Grund dafür ist häufig, dass die Eingabeaufforderung nicht detailliert genug beschrieben wurde. Denn was viele nicht wissen: Verschiedene KI-Parameter arbeiten im Hintergrund und beeinflussen das Ergebnis maßgeblich. Diese Parameter wollen aber gefüttert oder vielmehr „getriggert“ werden.
In diesem Beitrag soll es uns deshalb darum gehen, wie die drei Parameter Temperature, Top-P und Presence Penalty zusammenwirken und welchen Einfluss sie auf die Ergebnisse haben.
Tokenisierung bei KI-Modellen
Ehe wir uns anschauen, wie die verschiedenen KI-Parameter zusammenwirken, lohnt sich ein Blick auf die allgemeine Funktionsweise von LLMs. Diese arbeiten mit sog. Tokens. Tokens lassen sich am ehesten mit Silben vergleichen. Sowohl Ein- als auch Ausgabe werden in Tokens zerlegt, ein Wort besteht dabei im Schnitt aus 1-2 Tokens, ca. 30 Tokens bilden einen Satz. Visualisieren lässt sich dieser Vorgang mit dem Tokenizer von OpenAI.
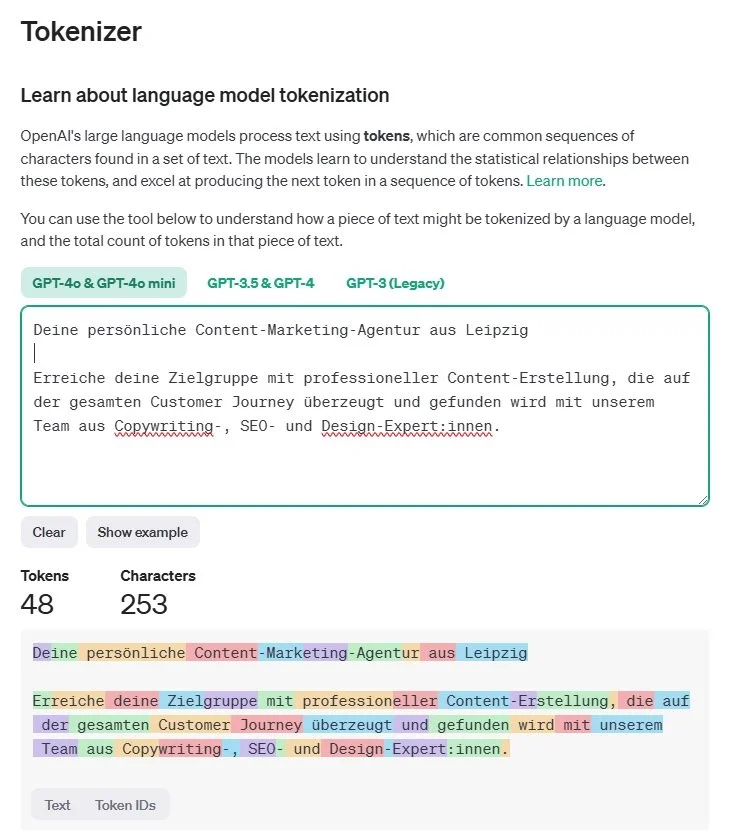
Hier habe ich mal den Teaser-Text von markop.de in den Tokenizer eingefügt. Die 253 Zeichen ergeben insgesamt 48 Tokens.
Es stellt sich womöglich die Frage, warum die Tokenisierung für das Verständnis von KI so wichtig ist. Hier ist die Antwort: Bei der Generierung eines Outputs folgt ein Token auf den vorherigen. Dabei stehen dem Sprachmodell je nach Umfang seiner Lerndatenbank verschiedene Möglichkeiten zur Verfügung. Welchen Token das Modell auswählt, basiert auf Wahrscheinlichkeiten.
Beispiel: Wir suchen nach der schönsten Stadt Deutschlands
Um diesen Prozess zu veranschaulichen, starten wir ein kleines Gedankenexperiment. Bitte vervollständigt einmal den folgenden Satz:
Die schönste Stadt Deutschlands ist …
Na, welche Antwort hattet ihr im Kopf? Natürlich gibt es hier nur eine richtige Lösung: Leipzig!
Spaß beiseite, je nach persönlichen Vorlieben, Empfindungen und Erfahrungen beendet jeder diesen Satz auf seine eigene Weise. Zwar hat die KI weder ein Bewusstsein noch kann sie auf einen persönlichen Erfahrungsschatz zurückgreifen, für eine Antwort müsste sie sich aber trotzdem für eine Stadt entscheiden – zumindest wenn wir sie per Prompt dazu zwingen.
Ihre Antwort basiert vermutlich auf dem Begriff, der statistisch am häufigsten genannt wird. Ihre Wahl könnte also ebenso auf Leipzig fallen, zur Auswahl stünden aber auch noch Berlin, Hamburg, München usw. Letztendlich entscheidet sich die KI für Heidelberg.

Hinweis: Ich habe diesen Vorgang zehnmal wiederholt, das Ergebnis war jedes Mal dasselbe. Das wird später noch einmal wichtig.
Für unser Beispiel spielt es übrigens keine Rolle, ob eine Antwort aus einem oder mehreren Tokens besteht. Dass z. B. auf den Token „Mün“ ein weiterer Token „chen“ folgt und die Antwort in Gänze „München“ ergibt, ist überaus wahrscheinlich – in diesem Kontext sind andere Antwortmöglichkeiten nahezu ausgeschlossen.
Welchen Einfluss haben KI-Parameter auf die Auswahl von Tokens?
Die KI-Parameter Temperature, Top-P und Presence Penalty stammen ursprünglich aus dem OpenAI Playground. Ihnen allen gemein ist, dass sie die Auswahl von Tokens und den damit verbundenen Output maßgebend beeinflussen. Mit ihnen lässt sich bestimmen, ob die KI ein komplett austauschbares Ergebnis generiert oder einen vollkommen ausgefallenen Text erstellt, der in erster Linie an einen Fiebertraum erinnert. Der gewünschte Output dürfte häufig in der Mitte liegen.
Herausforderungen im Umgang mit KI-Parametern
Im OpenAI Playground lassen sich Temperature, Top-P und Presence Penalty mithilfe von Reglern steuern. In ChatGPT ist das nicht der Fall. Hier wirken die Parameter eher im Hintergrund. Das bedeutet, dass ihr keinen direkten Einfluss auf die Stellgrößen nehmen könnt und eure Prompts mit entsprechenden Triggern ausstatten müsst.
Temperature, Top-P und Presence Penalty im Überblick
So, genug der Vorrede! Schauen wir uns an, was die drei KI-Parameter voneinander unterscheidet und wie ihr sie nutzen könnt.
Temperature
Die Temperature bestimmt die Zufälligkeit der von der KI generierten Antworten. Eine hohe Temperature führt dazu, dass das LLM auch unwahrscheinlichere Antwortmöglichkeiten einbezieht. Die Ergebnisse werden daher weniger vorhersehbar, was vor allem dann gut sein kann, wenn bei der Texterstellung Kreativität gefragt ist. Kommt es dagegen auf die Verlässlichkeit von Aussagen an, ist eine niedrige Temperature zu empfehlen.
Triggerwörter
Niedrig
"Reproduzierbar" , "Fakten"
"Definition"
"Eindeutig"
"Präzise"
"Unmissverständlich"
"Objektiv"
"Standardantwort"
"Konventionell"
Hoch
"Spekulativ"
"Experimentell"
"Unvorhersehbar"
"Kreativ"
"Bunt"
"Freigeist"
"Abenteuerlich"
"Surreal"
"Improvisiert"
Top-P
Die Top-P beeinflusst die Wortwahl der KI. Sorgt eine niedrige Top-P für einen gesetzten und nüchternen O-Ton, kann eine Erhöhung zu einer sehr ausgefallenen Ausdrucksweise, bis hin zu Fantasiesprache führen.
Triggerwörter
Niedrig
"Fundament"
"Basiswissen"
"Kerninformation"
"Hauptsache"
"Einfach"
"Essenziell"
"Zentral"
"Schlicht"
"Grundlegend"
Hoch
"Umfassend"
"Vielfältig"
"Ausführlich"
"Komplex"
"Zufällig"
"Breit gefächert"
"Uneingeschränkt"
"Detailreich"
"Offen"
Presence Penalty
Die Presence Penalty bestimmt, ob neue Ideen in den Erstellungsprozess einbezogen werden. Ist sie besonders hoch, „bestraft“ die KI ausschweifende Ideen und verlässt sich auf bewährte Aussagen. Neue Ideen und Konzepte werden vor allem dann einbezogen, wenn eine niedrige Presence Penalty gewählt wird. Das kann zum Beispiel beim Brainstorming von Vorteil sein. Es besteht aber auch die Gefahr, dass die KI halluziniert und Ideen entwickelt, die nachweisbar falsch oder schlicht nicht sinnhaft sind.
Triggerwörter
Niedrig
"Ungewöhnlich"
"Andersartig"
"Neu"
"Alternativ"
"Vielfältig"
"Einzigartig"
"Frisch"
"Abweichend"
"Kreativ"
Hoch
"Konsistent"
"Wiederkehrend"
"Fokussiert"
"Vertiefend"
"Beharrlich"
"Bekannt"
"Beständig"
"Repetitiv"
"Gewohnt"
Übrigens: Die Begriffe habe ich mir nicht ausgedacht. Ich habe einfach ChatGPT nach Triggerwörtern für jeden Parameter gefragt – die Ergebnisse stammen sozusagen „aus erster Hand“. 😉
Beispiel: Neue schönste Städte
Oben hatte ChatGPT noch Heidelberg als die schönste Stadt Deutschlands bestimmt. Wenn wir die KI anweisen, auch ungewöhnliche Ergebnisse einzubeziehen (Stichwort: niedrige Presence Penalty), dann vergibt die KI diesen Titel plötzlich an Bamberg!

Wir wiederholen den Vorgang: derselbe Prompt, ein anderes Ergebnis.

Zur Erinnerung: Ohne Anpassung des Prompts war es auch mit 10 Wiederholungen nicht möglich, die KI von einem anderen Ergebnis als Heidelberg zu überzeugen. Eine kleine Ergänzung des Prompts brachte dagegen komplett neue Ergebnisse.
Wichtig: Da wir die KI-Parameter in ChatGPT nicht über Schieberegler steuern, ist eine klare Trennung von Temperature, Top-P und Presence Penalty in der Praxis kaum möglich. Ein Trigger, der z.B. für die Anhebung oder Senkung der Temperature gedacht ist, kann auch Einfluss auf die anderen beiden Parameter haben. Letztendlich wirken die Größen immer zusammen!
Einordnung
Ehe ich zum Ende komme, will ich versuchen, die Thematik der KI-Parameter noch ein Stück weit einzuordnen. Dabei handelt es sich nur um meine persönliche Meinung.
Finde ich es gut, dass Temperature, Top-P und Presence Penalty sich in ChatGPT nicht präzise über Regler oder andere Steuerelemente definieren lassen? Für mich ein klarer Fall von „kommt drauf an.“
Einerseits bin ich diese Form der Steuerung von etlichen Tools aus anderen Bereichen gewohnt. Man müsse sich nur mal vorstellen, wenn man z.B. in der Bearbeitung von Webseiten für alles einen extra Steuerbefehl bräuchte – dies wäre keine Welt, in der ich leben möchte!
Zugegeben: Im täglichen Umgang mit ChatGPT vermisse ich die Einfachheit von Reglern hin und wieder. Ich muss aber sagen, dass ich gerade in der Inkonsistenz von generativer KI eine ihre größten Stärken sehe. Dass ich mit minimalen Anpassungen meines Prompts derart unterschiedliche Ergebnisse zutage fördern kann, empfinde ich als großen Gewinn.
Zudem sehe ich in der Steuerung mit Reglern ein weiteres Problem: Ich greife vor. Wenn ich z. B. die Kreativität der KI von vornherein einschränke, welchen Wert hat es dann noch, dass ich die KI in meinem Prompt anweise, sie solle etwas vollkommen Neues kreieren? Stünde das nicht im Widerspruch? Vielleicht hat man sich bei OpenAI genau deshalb auf die Restriktion durch Sprache beschränkt und die Regler weggelassen, die es im OpenAI Playground sehr wohl gibt.
Fazit
Mit diesem Beitrag wollte ich ein tieferes Verständnis für die Funktionsweise der Tokenisierung und der KI-Parameter schaffen. Ich hoffe sehr, das ist mir geglückt! Wir haben gesehen, welche Auswirkungen der Einbau eines Triggers in einen Prompt haben kann. Dieses Wissen könnt ihr zukünftig bei euren Prompts nutzen und euren Output hoffentlich noch präziser steuern.
Häufig gestellte Fragen zum Thema KI-Parameter
Was sind KI-Parameter wie Temperature, Top-P und Presence Penalty?
Diese Parameter beeinflussen, wie eine KI wie ChatGPT Antworten generiert. Sie steuern die Kreativität, die Diversität der Wortwahl und die Einbeziehung neuer Ideen.
Warum sind KI-Parameter wichtig für die Generierung von Texten?
Sie bestimmen maßgeblich, ob eine KI standardisierte, kreative oder völlig unkonventionelle Ergebnisse liefert. Je nach Zielsetzung können sie die Qualität und Präzision des Outputs verbessern.
Wie funktioniert die Tokenisierung in KI-Modellen?
Tokenisierung ist der Prozess, bei dem Wörter in kleinere Einheiten, sogenannte Tokens, zerlegt werden. Dies ermöglicht der KI, Wahrscheinlichkeiten für die nächsten Tokens zu berechnen und Antworten zu generieren.